7.7 CXL Fabric Architecture
这一节引入了 CXL 架构的一项重大演进,旨在将其从一个节点内的互连技术,扩展为一个机柜级别 (rack-level) 的互连Fabric。
设计目标:
- 应对高计算需求: CXL Fabric 架构的提出,是为了满足机器学习/AI、药物研发、气候建模等领域日益增长的巨大计算需求。
- 构建可组合系统: 它为构建灵活、可组合的机架规模系统提供了一条稳健的路径,这些系统可以利用简单的加载/存储内存语义或无序 I/O (UIO) 进行通信。
核心架构变更:
- 为了实现上述目标,CXL Fabric 引入了以下几个主要的技术变革:
- 扩展 Fabric 规模: 使用基于端口的路由 (Port Based Routing, PBR) 和 12 位 PID (Port ID) 来扩展 Fabric 的规模,理论上可以唯一识别多达 4096 个边缘端口 (Edge Ports)。
- 支持 G-FAM 设备: 引入了对 G-FAM 设备 (GFDs) 的支持。GFD 是一种可被所有主机和所有对等设备访问的高度可扩展的内存资源。
- 启用对等通信: 使用 UIO (Unordered I/O) 来启用主机和设备之间的对等网络通信。
系统宏观视图 (参考图 7-25)  一个典型的 CXL Fabric 系统由以下几部分组成:
一个典型的 CXL Fabric 系统由以下几部分组成:
- CXL Fabric: 由一个或多个相互连接的 Fabric 交换机组成。
- 交换机边缘端口 (SEP): Fabric 上的边缘端口,可以连接到 CXL 主机或 CXL/PCIe 设备。
- Fabric Manager (FM): 一个管理单元,连接到 CXL Fabric,并可能通过一个独立的管理网络连接到各个端点。
Fabric Manager (FM) 的核心职责
FM 在 CXL Fabric 架构中扮演着至关重要的角色:
- 初始化和设置: FM 负责整个 CXL Fabric 的初始化和设置。
- 资源分配: FM 负责将设备分配给不同的虚拟层次结构 (Virtual Hierarchies)。
- 动态重组: 在系统启动后,FM 可以通过 Fabric 的绑定和解绑操作,动态地向系统中添加或移除设备。这些变更会以管理型热添加 (Hot-Add) 和热移除 (Hot-Remove) 事件的形式呈现给主机。
域和一致性
- CXL Fabric 上的根端口可以属于相同或不同的域。
- 跨不同域的根端口之间,硬件缓存一致性不是一个强制要求。
- 然而,支持共享的设备(如 MLD、多头设备和 GFD)可以支持跨多个域的硬件管理缓存一致性。
7.7.1 CXL Fabric Use Case Examples
- 7.7.1.1 机器学习加速器 (Machine-learning Accelerators)
这个用例展示了如何使用 CXL Fabric 连接多个机器学习加速器集群。 
- 场景描述:
- 在这个系统中(如图 7-26 所示),多个加速器 (Acc) 和它们各自的主机 (Host) 通过一个专用的 CXL Fabric 互连。
- Fabric 的底层还连接了多个全局 Fabric 附加内存设备 (GFDs),作为共享内存池。
- 通信方式:
- 设备间直接通信: 加速器之间可以使用 UIO (Unordered I/O) 事务,通过 CXL Fabric 直接访问彼此的内存或共享的 GFD 内存,无需主机CPU的干预,从而实现低延迟通信。
- 一致性模型:
- 域内: 每个主机及其直接关联的加速器属于同一个“域”,域内通过 CXL 链路保持硬件缓存一致性。
- 跨域: 不同域之间的加速器通信(例如,一个加速器访问另一个加速器的内存)则采用 I/O 一致性模型。这意味着,如果一个设备缓存了来自另一个设备内存的数据,则需要通过软件(如适当的缓存刷新和屏障指令)来管理数据一致性。
- 7.7.1.2 HPC/数据分析用例 (HPC/Analytics Use Case)
这个用例聚焦于高性能计算和大数据分析领域,强调主机间通信和大规模内存共享。 
- 场景描述:
- 系统中包含多个主机、加速器、GFD 共享内存,以及连接到外部网络的 NIC(网络接口卡),所有这些都通过 CXL Fabric 连接(如图 7-27 所示)。
- 通信方式:
- 主机间通信: CXL Fabric 为主机与主机之间的直接通信提供了高效路径。
- 访问共享内存: 主机可以使用 CXL.mem 或 UIO 事务来访问 GFDs 上的共享内存。
- 网络直通内存: NIC 可以使用 UIO 事务,将数据从外部网络存储直接移动到 G-FAM 设备中,实现了“存算分离”和高效的数据加载。
- 一致性模型:
- 对于共享内存,一些 G-FAM 的实现可能会启用跨域的硬件缓存一致性,但也可以继续使用软件来管理一致性。
- 7.7.1.3 可组合系统 (Composable Systems)
这个用例展示了 CXL Fabric 如何构建灵活的、软件定义的“可组合系统”。 
- 场景描述:
- 采用多级交换机的架构(如图 7-28 中的叶脊网络 Leaf/Spine),所有的计算和存储资源(如 CPU、加速器、内存、GFD)都连接在底层的叶交换机上。
- 系统构建方式:
- 灵活组合: 系统可以动态地将位于同一个叶交换机下的资源组合起来,以实现低延迟的系统部署。
- 跨域/G-FAM 访问: 当需要跨域访问或访问全局共享的 G-FAM 时,流量才会通过上层的脊交换机进行转发。
- 通信限制:
- 跨越不同域的流量被限制为 CXL.mem 和 UIO 事务。
- 所有设备都必须被绑定到一个主机或由 FM 管理。
- 核心优势:
- 支持多级交换机和 PBR(基于端口的路由)为构建软件可组合系统提供了强大的能力。
7.7.2 Global-Fabric-Attached Memory (G-FAM)
7.7.2.1 概述 (Overview)
该小节详细定义了 G-FAM(全局 Fabric 附加内存)这一核心概念的特性、行为和关键机制。
- G-FAM 的定义: G-FAM 是一种可被 CXL Fabric 内所有主机和对等设备访问的高度可扩展的内存资源。
- 共享与一致性:
- G-FAM 的内存范围可以被独占地分配给单个请求者,也可以被多个请求者共享。
- 当内存被共享时,多请求者之间的缓存一致性可以由软件或硬件来管理。
- 访问权限由请求者边缘端口的解码器和目标 GFD(实现 G-FAM 的设备)共同强制执行。
- 访问协议:
- 来自多个域的主机/对等设备可以使用 CXL.mem 协议访问 GFD 的 HDM(主机管理的设备内存)空间。
- 来自多个域的对等设备可以使用 CXL.io UIO(无序 I/O) 协议访问。
- GFD 设备的关键特性:
- 无 PCIe 配置空间: GFD 设备没有传统的 PCIe 配置空间。
- 管理方式: 它们通过边缘交换机上行端口中的 GAE (Global Memory Access Endpoints) 或带外机制进行配置和管理。
- 与 MLD 的核心区别:
- GFD 拥有一个对所有请求者通用的设备物理地址 (DPA) 空间。
- 相比之下,MLD(多逻辑设备)为每个主机/对等接口(即每个 LD)都提供一个独立的 DPA 空间。
- 地址转换:
- GFD 负责将传入请求中的主机物理地址 (HPA) 转换为其内部的 DPA。
- 这个转换过程依赖于存储在 GFD 解码器表 (GFD Decoder Table) 中的、针对每个请求者的转换信息。
- 通过将来自不同请求者的多个 HPA 范围映射到同一个 DPA 范围,就可以创建共享内存。
- 请求者识别 (RPID):
- GFD 通过请求中的源端口 ID (SPID) 来识别请求者,这个 SPID 在此上下文中被称为 RPID (Requester PID)。
- 容量管理:
- GFD 上的所有内存容量都由动态容量 (Dynamic Capacity, DC) 机制来管理。
- 每个请求者最多可以访问 8 个非重叠的解码器。
- 交错 (Interleaving):
- G-FAM 内存范围可以在 2 到 256 个 GFD 之间进行交错(必须是2的幂)。
- 交错粒度可以是 256B、512B、1 KB、2 KB、4 KB、8 KB 或 16 KB。
7.7.2.2 Host Physical Address View (主机物理地址视图)
这一节描述了从主机 (Host) 的角度来看,G-FAM 内存是如何被组织和访问的。

核心概念:Fabric 地址空间
- 为了访问 G-FAM,主机必须在其自身的主机物理地址 (HPA) 空间中,划拨出一个连续的地址范围,这个范围被称为 "Fabric 地址空间"。
- 这个地址空间的起始和结束位置由
FabricBase和FabricLimit这两个寄存器来定义。
- 所有地址落在
FabricBase和FabricLimit之间(含边界)的主机请求,都会被路由到一个选定的 CXL 端口,进而进入 CXL Fabric。
分段与路由机制
这个路由过程的核心发生在主机所连接的边缘交换机上行端口 (PBR Edge USP) 中:
- 地址空间分段 (Segmentation): 在边缘交换机内部,上述的 "Fabric 地址空间" 被进一步划分为 N 个大小相等的段 (Segment)。
- 段的属性:
- 段的大小可以是 64 GB 到 8 TB 之间的任意 2 的幂次方值,并且必须是自然对齐的。
- 一个交换机支持的段的数量由其具体实现决定。
- 段与 GFD 的关联: 每个段都会被关联到一个特定的 GFD 设备,或者一个由多个 GFD 组成的交错集 (Interleave Set)。
- 请求路由: 当一个请求到达边缘交换机时,交换机会根据请求的 HPA 地址落在哪一个段内,来决定将这个请求路由到哪个 GFD 或 GFD 集合。这个过程依赖于一个名为 FAST (Fabric Address Segment Table) 的表。
重要说明
- 地址空间不匹配: 一个段的地址空间大小可能大于其关联的 GFD 的实际可用内存大小。在这种情况下,如果请求的地址超出了 GFD 的可访问范围,该请求会在 GFD 处解码失败。
- 交错的独立性: 主机跨多个根端口进行的交错(Host Interleaving)与 Fabric 内跨多个 GFD 进行的交错(GFD Interleaving)是完全独立的两种机制。
- 配置要求: 如果主机使用了根端口交错,那么所有相关 PBR 边缘交换机中的
FabricBase,FabricLimit和段大小都必须配置成完全相同的值。
7.7.2.3 G-FAM 容量管理 (G-FAM 容量管理)
这一节描述了 GFD (Global-Fabric-Attached Device) 内部的内存容量是如何被组织、划分和管理的。
管理方式和核心机制
- 管理接口: GFD 和其他 CXL 组件一样,通过 CCI (命令控制接口) 进行管理。
- 完全依赖动态容量: G-FAM 完全依赖于动态容量 (Dynamic Capacity, DC) 机制进行容量管理。与一些设备不同,GFD 没有“传统的”静态容量。
- 与 LD-FAM 的异同: G-FAM 的动态容量管理在概念上与 LD-FAM (用于 MLD 的动态容量) 有很多共通之处,例如都有 DC 区域、区段 (Extents) 和块 (Blocks) 的概念。但它们的管理命令和操作流程有显著不同。
设备介质分区 (Device Media Partitions, DMPs)
这是 G-FAM 容量管理的核心组织单位。
- 单一 DPA 空间: 与 MLD 为每个逻辑设备 (LD) 提供独立 DPA 空间不同,一个 GFD 只有一个对所有主机通用的 DPA (设备物理地址) 空间。
- DMP 的定义: 这个通用的 DPA 空间被组织成 1 到 4 个 DMP (设备介质分区)。每个 DMP 是一个具有特定属性的 DPA 地址范围。
- DMP 的属性:
- 介质类型: 一个基本的 DMP 属性是其物理存储介质的类型,例如是 DRAM 还是 PM (持久性内存)。
- 块大小: 另一个由 Fabric Manager (FM) 配置的重要属性是该分区的动态容量块 (DC Block) 大小。
- DMP 与 DC 区域的关系:
- 分配给某个主机的动态容量区域 (DC Region),由单个 DMP 的全部或部分组成。
- DC 区域会继承其所属 DMP 的所有属性(如介质类型和块大小)。
 图 7-30 直观地展示了这种关系。图中一个 GFD 的 DPA 空间被分成了多个 DMP,每个 DMP 有不同的属性(例如,一个是 PM 介质,块大小 256M;另一个是 DRAM 介质,块大小 64M)。然后,主机 0 的不同 DC 区域(Region A, B, C, D)分别映射到这些不同的 DMP 上,从而让主机可以使用具有不同特性的内存分区。
图 7-30 直观地展示了这种关系。图中一个 GFD 的 DPA 空间被分成了多个 DMP,每个 DMP 有不同的属性(例如,一个是 PM 介质,块大小 256M;另一个是 DRAM 介质,块大小 64M)。然后,主机 0 的不同 DC 区域(Region A, B, C, D)分别映射到这些不同的 DMP 上,从而让主机可以使用具有不同特性的内存分区。
与 LD-FAM 管理的主要区别
- LD-FAM 的动态容量管理是将内存分配和绑定到特定主机 ID 这两个操作一次性完成。
- GFD 则分为两步:首先将动态容量分配给一个命名的内存组 (Memory Group),然后再将特定的主机 ID 绑定到这个命名好的内存组上。
7.7.2.4 G-FAM Request Routing, Interleaving, and Address Translations (G-FAM 请求路由、交错和地址转换)
这是一个技术性非常强的部分,它详细描述了一个 G-FAM 请求从发起(由主机或对等设备)到被 GFD 设备处理,再到 GFD 发回响应(如窥探请求)的完整生命周期。这个过程的核心是两次关键的地址转换。
整个流程可以分为三个主要阶段,参考图 7-31: 
阶段一:请求在边缘交换机中的处理(HPA -> DPID)
当一个主机或对等设备发出一个访问 G-FAM 的请求时,这个请求首先到达它所连接的边缘交换机(对于主机是 Edge USP,对于对等设备是 Edge DSP)。边缘交换机的首要任务是根据请求的主机物理地址 (HPA),确定目标 GFD 设备的端口 ID (DPID)。
这个过程依赖两个关键的表格:
FAST (Fabric Address Segment Table) - Fabric 地址段表:
- 交换机首先使用 HPA 地址的一部分作为索引来查找 FAST 表。
- FAST 表中的每个条目对应一个地址“段”,并包含以下信息:
- 有效位 (Valid bit)。
- 交错方式 (Intlv): 定义了 GFD 的交错路数(例如 2-way, 4-way, ... , 256-way)。
- 交错粒度 (Gran): 定义了交错的块大小(例如 256B, 4KB 等)。
- DPID/IX: 如果不使用交错,这里直接就是目标 GFD 的 DPID。如果使用交错,这里则是一个指向 IDT 表的索引。
IDT (Interleave DPID Table) - 交错 DPID 表:
- 如果 FAST 条目指示了交错,交换机会根据 HPA、交错方式和粒度计算出具体的“路 (Way)”。
- 然后,用 FAST 条目中的 DPID/IX 加上计算出的“路”,得到一个最终的索引,用这个索引去查找 IDT 表。
- IDT 表中的条目即为最终要路由到的 GFD 的 DPID。
完成这个过程后,边缘交换机会将包含目标 DPID、自身 SPID (源端口 ID) 和未经修改的原始 HPA 的请求发送到 CXL Fabric 中。
阶段二:请求在 GFD 设备中的处理(HPA -> DPA)
当 GFD 设备收到请求后,它需要执行第二次地址转换,将请求中的 HPA 转换为 GFD 内部的设备物理地址 (DPA)。
GDT (GFD Decoder Table) - GFD 解码器表:
- GFD 使用请求中的 SPID(代表了请求者的身份)来访问其内部的 GDT 表,以选择专用于该请求者的解码器。
- GFD 可以为每个请求者配置多达 8 个解码器。
HPA 到 DPA 的转换:
- GFD 的解码器并行工作,将请求的 HPA 与每个解码器的 HPA 范围进行比较。
- 为了匹配,解码器会先从 HPA 中“移除”交错位,计算出一个偏移量。
- 如果 HPA 成功匹配上一个唯一的解码器,GFD 就会根据该解码器的信息(如 DPA 基地址和计算出的偏移量)计算出最终的 DPA。
访问检查:
- 在计算出 DPA 后,GFD 会使用其内部的动态容量访问保护机制(如 7.7.2.5 节所述的内存组)来检查该请求者是否有权限访问这个 DPA 地址。
阶段三:GFD 发回响应(窥探)的处理(DPA -> HPA)
当 GFD 需要向主机/对等设备发起一个窥探请求(如 BISnp)时,它需要执行上述过程的逆操作。
DPA 到 HPA 的转换:
- GFD 使用内部的 DPA 地址,在其 GDT 表中查找匹配的解码器。
- 找到匹配项后,它会执行逆向转换,即通过 DPA 偏移量和交错信息,“重新插入”交错位,最终计算出原始的 HPA。
发送窥探请求:
- GFD 将生成的窥探请求发送回 Fabric。此时,消息的 DPID 是原始请求者的 PID(由 GFD 的窥探过滤器记录),而 SPID 则是 GFD 自己的 PID。
边缘交换机处理:
- 边缘交换机收到窥探请求后,进行可选的 HPA 检查,然后移除 PTH(即 DPID/SPID),并将窥探请求转发给最终的主机/对等设备。
7.7.2.5 G-FAM Access Protection (G-FAM 访问保护)。
这一节描述了为 G-FAM 这种全局共享内存设计的、至关重要的多层次安全访问保护机制,以确保只有被授权的主机或设备才能访问指定的内存区域。
三级分层保护模型 (参考图 7-32)
 G-FAM 的访问保护是一个分层的体系,共有三级:
G-FAM 的访问保护是一个分层的体系,共有三级:
第一级保护(在主机/对等设备端):
- 由请求者自己的页表 (page tables) 提供。
- 这提供了操作系统层面的、细粒度的保护,可以将每个进程能访问的 Fabric 地址空间限制在主机/对等设备可访问范围的一个子集内。
第二级保护(在边缘交换机端):
- 由 GAE (全局内存访问端点) 中的 GMV (Global Memory Mapping Vector) 提供。
- 此外,边缘交换机中的 FAST/IDT 路由表也必须被正确编程,请求才可能被路由到 GFD。
第三级保护(在 GFD 设备端):
- 由 GFD 设备自身实现,提供细粒度的保护。
- 本节内容重点讲解的就是这第三级保护机制。
GFD 内部的访问保护机制 (参考图 7-33)
 GFD 内部的保护机制设计精巧,以支持多达 4096 个 CXL 请求者。其核心是内存组 (Memory Groups) 的概念。
GFD 内部的保护机制设计精巧,以支持多达 4096 个 CXL 请求者。其核心是内存组 (Memory Groups) 的概念。
- 内存组 (Memory Group): 一个内存组是 GFD 内部一组设备内存块 (DMP blocks) 的集合,这个集合内的所有内存块被授权给同一组请求者访问。
这个机制通过两个关键的表格协同工作来实现:
MGT (Memory Group Tables) - 内存组表:
- 功能: 为 GFD 中的每一个内存块分配一个内存组 ID (GrpID)。
- 结构: 每个设备介质分区 (DMP) 都有一个独立的 MGT。 MGT 中的每个条目对应 DMP 中的一个内存块。
- 工作流程: 当一个带有 DPA(设备物理地址)的请求到达 GFD 时,GFD 首先确定 DPA 属于哪个 DMP,然后计算出块索引,并从对应的 MGT 中查找出这个内存块的 GrpID。
SAT (SPID Access Table) - SPID 访问表:
- 功能: 识别每个请求者被授权访问哪些内存组。
- 结构: SAT 表由请求者的 SPID (源端口 ID) 来索引。
- 工作流程: GFD 使用请求中的 SPID 来查询 SAT 表,从而得到一个名为 GrpAccVec (Group Access Vector) 的向量。这个向量就是一个权限列表,其中的每一位对应一个内存组,如果某位为 1,则表示该请求者有权访问对应的内存组。
最终的访问检查
GFD 会并行执行上述两个查找操作。在获取到请求地址对应的 GrpID 和请求者身份对应的 GrpAccVec 后,GFD 会执行最后一步检查:
- 检查 GrpAccVec 中由 GrpID 所索引的那一位是否为 1。
- 如果为 1,则访问被允许。
- 如果不为 1,则访问被拒绝。
通过这种方式,GFD 确保了对每一块内存的访问都经过了请求者身份和内存归属的双重验证。
实现建议
- 为了支持足够细粒度的 GFD 容量分配,建议设备为每个 MGT 实现至少 1K 个条目。
- 为了支持足够数量的、具有不同主机访问列表的内存范围,建议设备实现至少 64 个内存组。
7.7.2.6 Global Memory Access Endpoint (GAE, 全局内存访问端点)
GAE 是 CXL Fabric 架构中一个非常关键的组件,它扮演着主机与 G-FAM/GIM 资源之间的管理桥梁角色。
GAE 的定义和功能
- 定义: GAE 是一个邮箱命令控制接口 (Mailbox CCI),它使得主机能够访问 G-FAM(全局 Fabric 附加内存)和 GIM(全局集成内存)资源,并配置用于路由的 FAST 表。
- 呈现方式: GAE 以一个标准的 PCIe 端点 (Endpoint) 形式呈现给主机,拥有 Type 0 类型的配置空间。
GAE 的两种配置模式
主机边缘交换机 (Host Edge Switch) 的上行端口 (USP) 可以通过以下两种配置之一来暴露 GAE:
- 提供 LD-FAM 和 G-FAM/GIM 两种资源 (参考图 7-34)

- 在这种模式下,主机不仅能看到传统的 CXL 交换机结构(包含 USP vPPB 和 DSP vPPB),还会看到一个额外的 GAE 端点。
- 这个 GAE 用于配置 G-FAM/GIM 的访问,同时也可能包含管理本地 CXL 交换机(即 LD-FAM 资源)的命令。
- 仅提供 G-FAM/GIM 资源 (参考图 7-35)

- 在这种模式下,主机看到的是一个极简的结构。
- VCS 中没有实例化一个完整的 CXL 交换机,GAE 是呈现给主机的唯一 PCIe 功能。这种配置专用于访问 Fabric 资源。
GAE 的其他角色和机制
- 在下游交换机中的作用: 在下游边缘交换机 (Downstream ES) 的虚拟上行端口 (vUSP) 中,也必须要有一个 GAE。
- 这个 GAE 用于配置该下游 VCS,包括其内部的 FAST 和 LDST 表,并向主机提供 CDAT(能力数据表)信息。
- 访问控制向量: 每个 GAE 维护两个 4k 比特的访问向量,用以控制其所服务的主机是否有权访问某个特定的 PID:
- GMV (Global Memory Mapping Vector): 控制对 G-FAM 或 GIM 资源的访问权限。
- VTV (VendPrefixLO Target Vector): 控制对
VendPrefixLO目标的访问权限。
7.7.2.7 Event Notifications from GFDs (来自 GFD 的事件通知)
这一节描述了 GFD (全局 Fabric 附加内存设备) 是如何向主机报告事件的,其机制与传统设备不同。
- 无独立日志: GFD 设备不会为每一个请求者(主机)都维护一个独立的事件日志。
- 通知机制: GFD 使用一种名为 “增强事件通知” (Enhanced Event Notifications) 的机制来报告事件。
- 传输方式: 这些通知通过一种特殊的 GAM VDM (全局异步消息厂商定义消息) 在 Fabric 中进行传输。
- 投递到主机:
- 当一个事件通知需要发送给某个主机时,GAM VDM 的目标地址 (DPID) 会被设置为该主机的 GAE (全局内存访问端点) 的 PID。
- GAE 收到 GAM VDM 后,会将其 32 字节的负载内容写入到一个位于主机内存中的 GAM 缓冲区 (GAM Buffer) 中。
- GAM 缓冲区工作原理:
- 这是一个由主机配置和管理的环形缓冲区 (circular buffer)。
- GAE 通过一个“头指针”向缓冲区写入数据,而主机则通过移动一个“尾指针”来读取数据。
- 当缓冲区满时,GAE 不会覆盖旧的条目,直到主机读取并释放它们。 如果在缓冲区已满的情况下收到新的 GAM VDM,将会报告缓冲区溢出。
- 对等设备的限制: GAM VDM 不会被转发给对等设备(Peer Devices)。 如果目标是对等设备,其边缘交换机会将该消息静默丢弃。
7.7.3 Global Integrated Memory (GIM)
GIM,即全局集成内存,是 CXL Fabric 架构中与 G-FAM 并列的另一个核心概念,它主要用于实现跨主机域 (cross-domain) 的直接通信。
 GIM 的核心定义
GIM 的核心定义
- GIM 指的是一个远程主机域中的内存,被映射到本地主机的物理地址空间中。简单来说,就是让一个主机可以直接访问另一个主机的内存。
主要用途与限制
- 主要用途: GIM 主要用于实现跨域的远程 DMA 和消息传递。
- 非适用场景: 它不适用于内存池化或内存借用等用例。
- 访问协议:
- 访问 GIM 必须只能使用 UIO (Unordered I/O) 事务。
- 禁止使用 CXL.mem 或 CXL.cache 协议来访问 GIM。
- 一致性模型:
- 跨域访问被认为是 I/O 一致的,意味着数据在访问时刻是一致的。
- 这要求远程域要么将这部分内存标记为不可缓存,要么通过软件机制来管理缓存。
在地址空间中的位置
- 访问 GIM 和 GFD(G-FAM 设备)的主机,必须将这两者都映射在主机物理地址 (HPA) 空间中一个名为 "Fabric Address Space" 的连续地址范围内。
7.7.3.1 Host GIM Physical Address View (主机 GIM 物理地址视图)。
这一节描述了 GIM(全局集成内存)是如何被映射到主机的物理地址空间中,以及主机如何通过这个地址视图来访问 GIM。
核心机制:使用 Fabric 地址空间
- 主要访问方式: 当主机需要访问 GIM 并且依赖交换机中的地址解码器进行路由时,它必须将 GIM 的地址范围映射到其物理地址 (HPA) 空间中的 "Fabric Address Space" (Fabric 地址空间) 内。
- 与 G-FAM 共存: 如果一个主机同时需要访问 G-FAM 和 GIM,那么这两个地址范围都必须被包含在一个连续的 Fabric 地址空间中。
- 解码器: 主机和设备对 GFD (G-FAM) 和 GIM 的访问,都使用一个通用的 FAST 解码器来确定目标的 DPID(目标端口ID)。
 图 7-37 非常直观地展示了这一点:
图 7-37 非常直观地展示了这一点:
- 在主机的物理地址视图中,"Fabric Address Space" 内部被进一步细分。
- 一部分是 "Global Fabric Attached Memory" (用于 G-FAM),由段 0 到段 N-1 组成。
- 另一部分是 "Global Integrated Memory" (用于 GIM),由段 N 到段 M-1 组成。
- 这表明,从主机的角度看,GIM 和 G-FAM 共享同一套基于“段”和 FAST 表的地址解码和路由机制。
备用机制:绕过交换机解码器
- 文件也提到了一种备用的访问方式。
- 主机和设备可以使用专有的 (proprietary) 解码机制来自己确定目标的 DPID,从而绕过交换机入口端口的地址解码器(如 FAST)。
- 这种方式通常被限制在同构(homogeneous)的对等设备之间进行访问。
7.7.3.2 Use Cases (用例)
这一节通过两个具体的例子,阐述了 GIM (全局集成内存) 在实际应用中如何实现跨域通信。
用例一:多主机 CXL 集群 (参考图 7-38) 
- 应用场景:
- 机器学习 (ML) 和高性能计算 (HPC) 应用通常需要分布在多个计算节点上运行。
- 这些应用需要一个可扩展且高效的网络,以实现低延迟的通信和同步。
- GIM 的作用:
- 在一个由多个计算节点组成的集群中,每个主机可以将其部分或全部可用内存作为 GIM 暴露给其他计算节点。
- 如图 7-38 所示,每个计算节点(由一个主机 Host 和一个加速器 Acc 组成)都可以将其内存(图中标记为 GIM 的部分)共享到 CXL Fabric 中,从而允许其他节点直接访问。
用例二:跨域设备间通信 (参考图 7-39) 
- 应用场景:
- 在一个 CXL Fabric 连接的机器学习集群中,加速器之间需要直接高效地通信。
- GIM 的作用:
- 在这个例子中,只有连接到加速器设备上的内存被作为 GIM 暴露给其他设备。
- UIO (Unordered I/O) 协议为在设备间实现类似 RDMA (远程直接内存访问) 的语义提供了灵活的实现选项。
- 如图 7-39 所示,多个加速器通过 CXL Fabric 互连,每个加速器上的内存可以被 Fabric 中的其他加速器直接访问,实现了跨域设备间的通信。
总结
GIM 构建了一个通用的框架,它利用同一套能力,支持了多种通信路径,包括:
- 主机到主机 (host-to-host)
- 设备到设备 (device-to-device)
- 主机到设备 (host-to-device)
- 设备到主机 (device-to-host)
7.7.3.3 Transaction Flows and Rules for GIM (GIM 的事务流和规则)。
这一节是理解 GIM (全局集成内存) 工作原理的关键,它定义了 GIM 访问的具体流程和交换机/设备必须遵守的规则。虽然示例图使用了主机到主机的访问,但这套流程和规则同样适用于主机到设备、设备到设备以及设备到主机的通信。
两种 GIM 访问流程
文件描述了两种实现 GIM 访问的流程,主要区别在于是否使用边缘交换机的 FAST 解码器。
流程一:使用 FAST 解码器进行访问 (参考图 7-40)  这是标准的、基于 Fabric 地址空间的访问方式。
这是标准的、基于 Fabric 地址空间的访问方式。
请求发起: Host 1 发出一个目标地址落在其 Fabric 地址空间内的 UIO 请求。
入口交换机处理:
- 请求到达 Host 1 所连接的边缘交换机(入口交换机)。
- 交换机的 FAST 解码器命中,确定了目标 Host 2 的 DPID (目标端口 ID)。
- 交换机在生成 PBR 头部 (PTH) 时,会设置一个特殊的标志位 PTH.PIF=1。
Fabric 内路由: 请求在 CXL Fabric 中被路由到目标所在的边缘交换机(出口交换机)。
出口交换机处理:
- 出口交换机收到请求后,检查到 PTH.PIF 位为 1。
- 它会将请求中的源 PID (PTH.SPID) 放入一个名为
VendPrefixLO的特殊 TLP 前缀中,然后将不带 PBR 头部的 TLP 转发给目标 Host 2。
返回完成包:
- Host 2 处理完请求后,会返回一个 UIO 完成包。这个完成包中也包含了带有原始请求者 PID 的
VendPrefixLO前缀。
- 这个完成包被路由回 Host 1 所在的边缘交换机,交换机利用
VendPrefixLO中的 PID 信息,将完成包正确地路由回 Host 1。
- Host 2 处理完请求后,会返回一个 UIO 完成包。这个完成包中也包含了带有原始请求者 PID 的
流程二:绕过 FAST 解码器进行访问 (参考图 7-41)  这是一种更直接的、通常用于受信任设备间的访问方式。
这是一种更直接的、通常用于受信任设备间的访问方式。
请求发起: Host 1(或一个受信任的设备)在发起 UIO 请求时,直接在 TLP 中包含了
VendPrefixLO前缀,并在前缀中指定了目标 Host 2 的 PID。
入口交换机处理:
- FM 必须预先将该入口端口配置为允许使用入口请求的
VendPrefixLO。
- 交换机收到这个带有前缀的请求后,绕过 FAST 地址解码,直接从
VendPrefixLO中提取 PID 作为 DPID,然后设置 PTH.PIF=1 并将请求转发到 Fabric 中。
- FM 必须预先将该入口端口配置为允许使用入口请求的
后续流程: 之后的路由和返回流程与流程一相同。
GIM 规则总结
为了实现上述流程,CXL 规范定义了一系列严格的规则:
- 通用规则:
- GIM 流程目前仅支持 UIO 事务。
- FM 负责在非 PBR 边缘端口上启用
VendPrefixLO的使用。
- 入口交换机端口的规则 (Ingress Port):
- 对于没有
VendPrefixLO但地址命中 FAST 的 UIO 请求,交换机在转发到 PBR Fabric 时必须将 PTH.PIF 位置为 1。
- 对于带有
VendPrefixLO的 UIO 请求,如果端口被授权,则交换机绕过解码,直接使用前缀中的 PID 作为 DPID。如果端口未被授权,则视作一个不支持的请求 (UR)。
- 对于没有
- 出口交换机端口的规则 (Egress Port):
- 对于收到的 PTH.PIF 位为 1 的 UIO 请求,出口交换机在转发到最终目标时,必须将源 PID 放在
VendPrefixLO前缀中(如果该出口端口被授权使用VendPrefixLO)。如果未被授权,则视作一个 UR。
- 如果收到的 UIO 请求的 PTH.PIF 位为 0,则无论端口是否授权,都不会添加
VendPrefixLO前缀。
- 对于收到的 PTH.PIF 位为 1 的 UIO 请求,出口交换机在转发到最终目标时,必须将源 PID 放在
- 主机/设备的规则:
- 支持
VendPrefixLO语义的主机/设备,在收到带有VendPrefixLO的 UIO 请求后,必须在返回的完成包中,使用相同的 PID 填充VendPrefixLO。
- 支持
7.7.5 HBR and PBR Switch Configurations (HBR 和 PBR 交换机配置)
这一节的核心内容是定义两种不同类型的 CXL 交换机,并阐述它们之间如何相互连接以及如何构建灵活的网络拓扑。
两种交换机类型
CXL 支持两种类型的交换机:
- HBR (Hierarchy Based Routing) - 基于层级的路由:
- 这是对 CXL 2.0 规范中引入的、遵循传统 PCIe 树状层级结构进行路由的交换机的简称。
- PBR (Port Based Routing) - 基于端口的路由:
- 这是为 CXL Fabric 织物架构引入的新型交换机,它使用 PID (端口 ID) 进行路由,可以构建更复杂的网络拓扑。
互连基本规则
文件列出了一系列关于这两种交换机如何与主机、设备等组件连接的基本规则,以确保系统可以正常工作:
- 主机根端口 (Host RP) 必须连接到 HBR USP、PBR USP 或一个非 GFD 设备。
- 非 GFD 设备 (如 SLD/MLD) 必须连接到 HBR DSP、PBR DSP 或一个主机根端口。
- PBR USP (PBR 交换机的上行端口) 只能连接到主机根端口;不支持连接到 HBR 交换机的下行端口。
- HBR USP (HBR 交换机的上行端口) 可以连接到主机根端口、PBR DSP 或另一个 HBR DSP。
- GFD (全局 Fabric 附加内存设备) 只能连接到 PBR DSP。
- PBR FPort (PBR 交换机之间的 Fabric 端口) 只能连接到另一个 PBR 交换机的 PBR FPort。
 图 7-42 展示了遵循上述规则的一些受支持的交换机配置示例,但并非全部。这些示例包括单个 PBR 交换机、多级 PBR 交换机、PBR 与 HBR 混合连接等多种拓扑。
图 7-42 展示了遵循上述规则的一些受支持的交换机配置示例,但并非全部。这些示例包括单个 PBR 交换机、多级 PBR 交换机、PBR 与 HBR 混合连接等多种拓扑。
PBR Fabric 拓扑的灵活性
使用 PBR 交换机时,CXL Fabric 的拓扑是非规定性的 (non-prescriptive),这意味着它可以自由地实现如胖树 (fat tree)、网状 (mesh)、环形 (ring) 等复杂的非树形拓扑。 然而,在这些包含环路 (loops) 的拓扑中,必须解决潜在的死锁 (deadlock) 问题。
网状拓扑示例 (图 7-43)
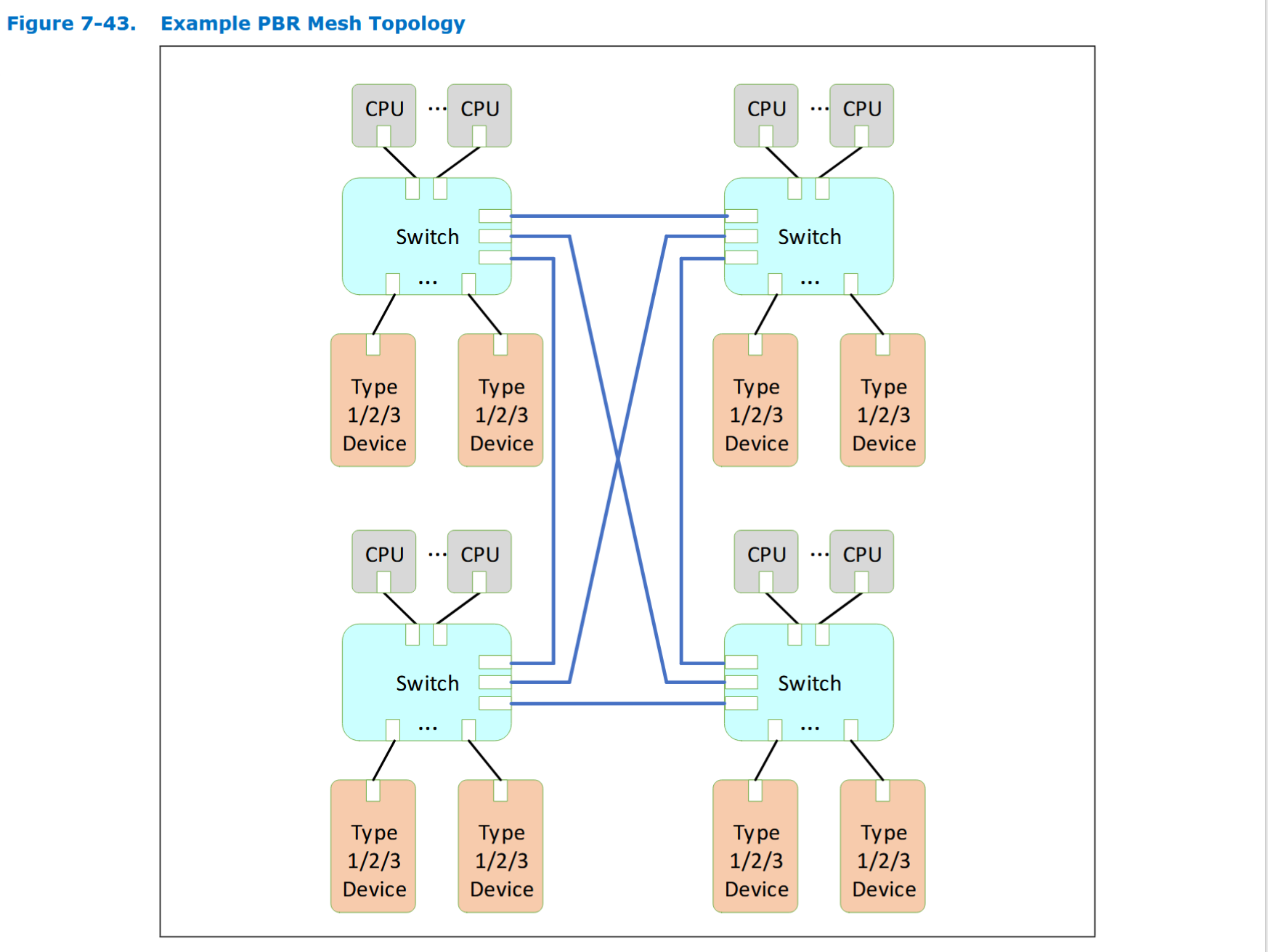
- 结构: 图 7-43 展示了一个由四个 PBR 交换机组成的全互连网状拓扑。 在这种结构中,每个交换机都与其他所有交换机直接相连。
- 优势: 这种拓扑的一个显著优点是,它可以在连接大量组件的同时,将任意两点之间的通信路径(即交换机跳数)限制在很短的范围内。
避免死锁的路由方案 (图 7-44)

- 问题: 在网状这类有环路的拓扑中,如果流量可以在交换机之间任意转发,就可能形成一个封闭的依赖循环,导致所有相关流量都卡住不动,即发生“死锁”。
- 解决方案: 为了避免死锁,FM 必须对路由进行规划。 图 7-44 通过在链路上增加箭头,展示了一种无死锁的路由方案。
- 箭头含义: 图中的箭头代表了允许的转发路径。 交换机被编程为只支持部分转发路径,从而主动破坏所有可能导致死锁的循环依赖。
- 具体例子: 文件中举例说明,一个从左下角交换机发往右上角交换机的消息有两条路可选:
通过直接链路。
通过左上角的交换机进行一次转发。
- 但这个消息不能通过右下角的交换机进行转发,因为图中没有画出相应的转发箭头。 这种受限制的路由选择,在提供多路径能力、保证带宽的同时,确保了网络的无死锁运行。
7.7.6 PBR Switching Details
7.7.6.1 Virtual Hierarchies Spanning a Fabric (跨 Fabric 的虚拟层次结构)。
这一节是理解 CXL Fabric 架构如何工作的核心关键。它解释了 CXL Fabric 如何通过“虚拟化”和“抽象化”的手段,向主机隐藏其底层的复杂物理拓扑。
核心理念:抽象化
- 隐藏复杂性: 主机连接到由 PBR 交换机组成的 CXL Fabric 时,它不需要任何特殊的、针对 Fabric 的发现机制。 Fabric 的所有复杂性都被抽象掉了。
- 呈现简单视图: 主机看到的是一个简化的、符合标准 PCIe 规范的交换拓扑。 所有中间的 Fabric 交换机对主机的视角来说都是不可见的。
主机看到的逻辑视图
从主机的角度来看,它最多能发现两层虚拟的“边缘交换机” (Edge Switches, ES):
主机边缘交换机 (Host ES):
- 这是主机发现的第一个交换机,代表它所连接到的 Fabric 边缘。
- 如果有其他端点设备 (EPs) 也物理连接在这个 PBR 交换机上,并且被绑定到该主机的虚拟层次结构 (VH) 中,那么这些设备看起来就像是直接连接在 Host ES 的 PPB 下。
下游边缘交换机 (Downstream ES):
- Fabric Manager (FM) 可以在 Host ES 的 VCS 和一个远程的 PBR 交换机之间建立绑定连接。
- 当这种绑定建立后,这个远程交换机会呈现一个 VCS,在主机看来,它就像是连接到了 Host ES 的一个虚拟下行端口 (vDSP) 上。
虚拟链路 (Virtual Link)
- 关键概念: 主机发现的只是连接 Host ES 的 vDSP 和 Downstream ES 的虚拟上行端口 (vUSP) 之间的一条单一虚拟链路。
- 无视物理路径: 无论这两个边缘交换机之间物理上是否存在、存在多少个中间 Fabric 交换机,主机看到的永远是这条单一的虚拟链路。
- 虚拟链路状态: 这条虚拟链路的状态由 Host ES 进行虚拟化。如果路径上的任何一个中间交换机间链路 (ISL) 断开,Host ES 就会在其对应的 vPPB 上向主机报告一个意外链路中断 (surprise Link Down) 错误。
与 HBR 交换机的区别
- 如果一个传统的 HBR 交换机连接到一个 PBR DSP 下,那么这个 HBR 交换机及其下的所有设备对主机来说是可见的。 HBR 交换机不是 Fabric 交换机,因此不会被抽象隐藏。
图 7-45 的直观解释 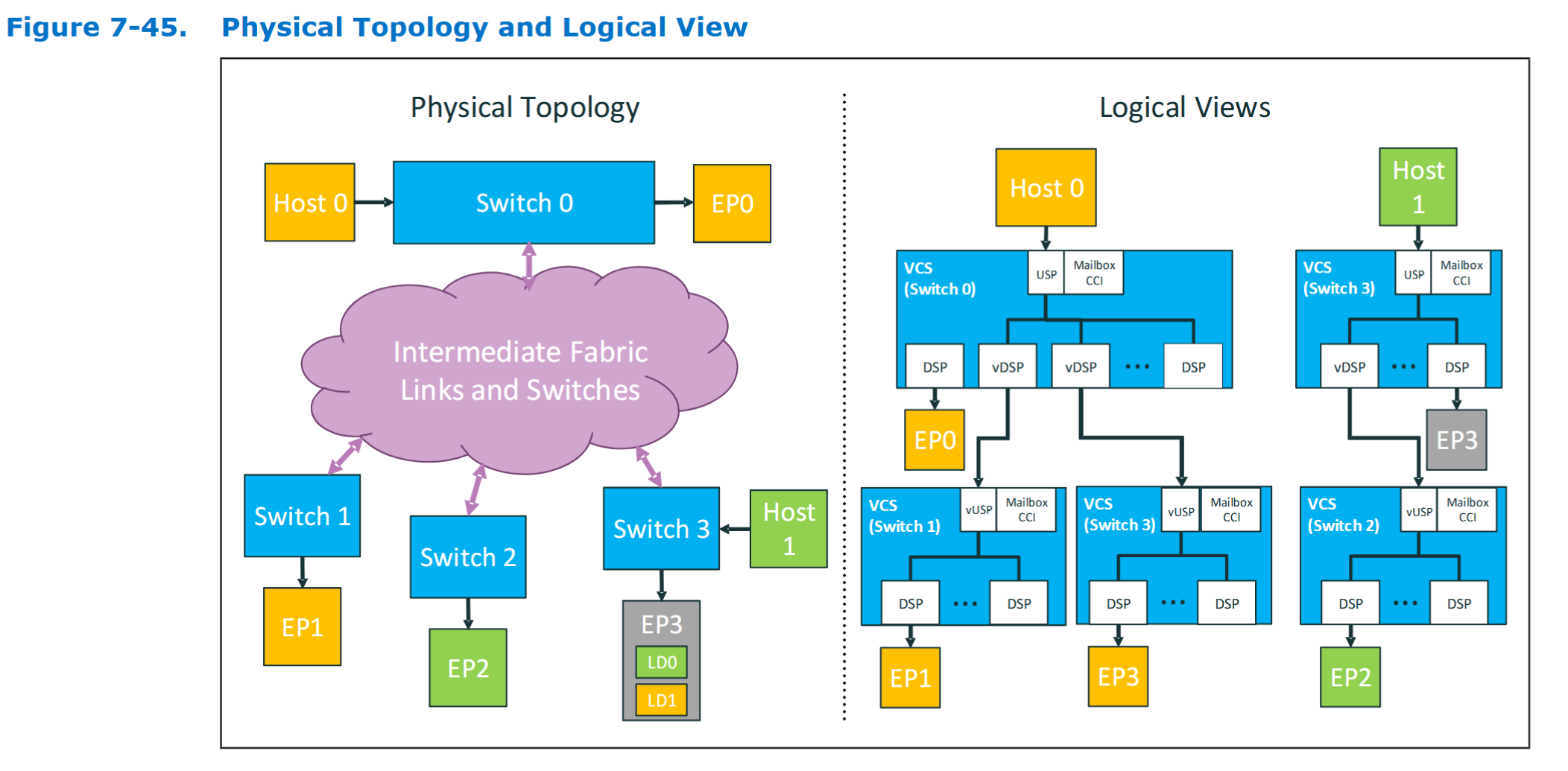 这张图完美地诠释了物理拓扑和逻辑视图的区别:
这张图完美地诠释了物理拓扑和逻辑视图的区别:
- 左侧 (Physical Topology): 展示了真实的、复杂的物理连接。Host 0 连接到 Switch 0,Host 1 连接到 Switch 3,而 Switch 0, 1, 2, 3 之间通过一个“中间 Fabric 链路和交换机”的云状网络互连。
- 右侧 (Logical Views): 展示了两个主机各自“看到”的景象。
- Host 0 的视角: 它只看到一个 Host ES (Switch 0)。它发现 EP0 设备直接连着自己这个交换机。同时,它还看到两个 Downstream ES(分别是 Switch 1 和 Switch 3),通过两条独立的虚拟链路连接到 Host ES 的两个 vDSP 上。
- Host 1 的视角: 它只看到 Host ES (Switch 3),并发现 EP3 设备直接相连。同时,它还看到了一个 Downstream ES (Switch 2)。
- 结论: 复杂的、网状的物理互连网络,在主机的逻辑视图中被简化成了清晰、独立的树状层次结构,大大降低了主机软件的复杂性。
7.7.6.2 跨 Fabric 的 PBR 消息路由
这一节定义了 PBR Fabric 中消息路由的两种主要方式和两种解码机制。
- 两种路由方式:
静态路由 (Static Routing): 消息在源和目标之间始终使用一条固定的路径。
动态路由 (Dynamic Routing): 消息在源和目标之间可以根据拥塞、链路状态等因素,动态地选择不同的路径。
- 两种解码和路由机制:
层级路由 (Hierarchical Routing):
- 消息在每个边缘交换机 (ES) 内部使用 HBR(基于层级)的机制进行解码和路由。
- 在边缘交换机之间,则通过 vDSP/vUSP 绑定进行静态路由。
边到边路由 (Edge-to-edge Routing):
- 消息从源边缘端口直接路由到目标边缘端口,使用在源端就已确定的 DPID。
- 它可以根据消息类别,采用静态或动态路由。
- 规则总结 (参考表 7-84):
- 大部分的 CXL.io TLP 使用层级路由。
- CXL.cache 消息和使用了 FAST/LDST 解码器的 CXL.mem 消息则使用边到边路由,以利用动态路由带来的优势。
- 使用 vDSP/vUSP 绑定的消息总是使用静态路由。
7.7.6.4 PBR 交换机 vDSP/vUSP 绑定与连接
这一节解释了 CXL Fabric 中一个核心的虚拟化机制:vDSP-vUSP 绑定。
- 核心概念: 这种绑定在主机端的边缘交换机 (Host ES) 的一个 VCS 和下游端的边缘交换机 (Downstream ES) 的一个 VCS 之间,创建了一个虚拟连接。
- 组件定义:
- vDSP (虚拟下行端口): 位于 Host ES 的 VCS 中,在主机看来它是一个普通的下行端口。
- vUSP (虚拟上行端口): 位于 Downstream ES 的 VCS 中,在主机看来它是一个普通的上行端口。
- 抽象效果:
- 主机看到的只是连接 vDSP 和 vUSP 的一条单一虚拟链路。
- 无论这两个边缘交换机之间物理上经过了多少个中间交换机,这条虚拟链路的概念都成立。
- 消息流:
- 下行: 从 Host ES 发往 Downstream ES 的消息,会包含 vDSP 绑定信息中定义的 SPID 和 DPID,然后在 Fabric 中以静态路由的方式传输,最终被匹配的 vUSP 接收。
- 上行: 从 Downstream ES 发往 Host ES 的 CXL.io 消息流程类似,但方向相反。
7.7.6.5 PID 使用模型和分配
这一节阐述了 12 位的 PID 在 Fabric 中是如何被分配给不同组件以实现路由的。PID 由 FM 分配或通过静态方式初始化。
- 主机边缘交换机上行端口 (Host ES USP): 通常有一个 PID,但也可以被分配多个 PID,以便与同一个下游边缘交换机建立多个不同的绑定。
- 下游边缘交换机 Fabric 端口 (Downstream ES FPort): 可以被分配一个或多个 PID,不同的 PID 可以关联到不同的物理 FPort 集合,以实现多路径。
- 边缘交换机下行端口 (Edge DSP):
- 连接非 GFD 设备的 DSP 通常有一个 PID。
- 连接 GFD 的 DSP 可能不需要专门的 PID,而是依赖 GFD 自己的 PID。
- GFD 设备: 可以被分配一个或多个 PID。
- vDSP/vUSP 绑定: 每个绑定都关联两个 PID:一个用于主机端的 USP,一个用于下游端的 FPort。
- 交换机和 FM: PBR 交换机自身和连接到它的 FM 也需要被分配 PID,用于管理通信。
- PID FFFh: 这是一个保留的 PID,用于指示一个事务应在本地处理,常用于初始设备发现阶段,此时设备可能还没有被分配一个有效的 PID。
7.7.9 PBR Support for UIO Direct P2P to HDM (PBR 对 UIO 直通 HDM 的支持)。
这一节描述了 CXL Fabric 架构中一个非常重要的功能:允许一个对等设备(Peer Device,通常指加速器)使用 UIO(无序 I/O)事务,直接读写另一个设备上的 HDM(主机管理的设备内存)。PBR 交换机为此提供了专门的高效路由机制。
核心目标与传统方式的对比
- 目标: 实现加速器到内存设备之间的高效、低延迟数据通路,无需主机 CPU 的干预。
- 传统方式 (HBR): 在 HBR 交换机中,这种 P2P 通信通常需要通过“层级路由”,流量可能需要先向上走到共同的根节点再向下走,效率较低。
- PBR 解决方案: PBR 交换机引入了边到边路由 (edge-to-edge routing) 的特殊机制,让流量可以直接从源设备的边缘交换机,穿过 Fabric,直达目标设备的边缘交换机。
为了实现这一目标,PBR 交换机引入了两个关键的新组件:LDST 解码器和基于 ID 的重路由器。
1. LDST (LD-FAM Segment Table) 解码器的作用 (请求路径)
LDST 是实现“请求”从加速器高效路由到远端内存的关键。
- 定义: LDST 的功能与之前提到的 FAST 解码器类似,但它专门用于将请求路由到 LD-FAM 设备(即 SLD 或 MLD)。
- 位置: LDST 可以部署在主机的边缘上行端口 (Edge USP) 中,也可以部署在连接加速器的边缘下行端口 (Edge DSP) 中。本节讨论的就是后者。
- 工作流程:
一个加速器发出一个 UIO 请求,目标是远端的一个 MLD 或 SLD 上的内存。
这个请求(采用 HBR 格式)首先到达与该加速器直连的 Edge DSP。
Edge DSP 内部的 LDST 解码器会根据请求的 HPA(主机物理地址)进行匹配。
匹配成功后,LDST 会将请求转换为 PBR 格式,并确定目标 LD-FAM 设备所在端口的 DPID (目标端口 ID)。
请求随后以边到边路由的方式,被高效地发送到目标设备所在的边缘交换机。
- PCIe 段号处理: LDST 还支持跨 PCIe 段的通信。主机软件可以配置 LDST,在需要时将请求者的段号插入到请求中,以便目标设备在返回完成包时能够包含正确的路由信息。
2. ID-Based Re-Router (基于 ID 的重路由器) 的作用 (完成包路径)
ID-Based Re-Router 则是为了让“完成包”能从内存设备高效地返回给发起请求的加速器。
- 问题: 如果没有这个机制,完成包默认会根据请求者的完整 PCIe ID(段号、总线号、设备号、功能号)进行层级路由,效率低下,尤其是在跨虚拟层次 (cross-VH) 的场景中。
- 解决方案:
- 在内存设备所连接的 Edge DSP 中,可以实现一个 ID-Based Re-Router。
- 当一个 UIO 完成包到达这个 Edge DSP 时,重路由器会使用完成包中的目标 ID(即原始请求者的 PCIe ID)进行内容寻址匹配 (CAM match)。
- 匹配成功后,重路由器会返回该请求者的 DPID。
- 交换机随后使用这个 DPID,将完成包以边到边路由的方式,直接高效地发送回发起请求的加速器所在的 Edge DSP。
3. 访问保护机制 (LAV)
为了确保这种强大的 P2P 功能是安全的,规范定义了相应的保护机制。
- LAV (LDST Access Vector): 这是一个 4k 比特的访问向量。
- 功能: 它由 Fabric Manager (FM) 控制,用于规定一个主机有权将哪些 PID 配置到其 LDST 或 ID-Based Re-Router 结构中。
- 流程: FM 必须先在 LAV 中为某个目标 PID 授权,之后主机才能配置到该 PID 的路由。这可以防止一个主机配置访问未授权设备的路径。
- 域验证: 对于跨虚拟层次的用例,FM 还需要负责使用域验证机制,以确认所有相关的虚拟层次都属于同一个可信的主机域。
7.7.12 PBR Fabric Management (PBR Fabric 管理)。
这一节是理解 CXL Fabric 如何从零开始被构建、发现和管理的核心流程章节。它描述了 Fabric Manager (FM) 在整个 Fabric 生命周期的关键作用和操作步骤。
7.7.12.1 Fabric 启动和初始化
与单个 HBR 交换机类似,PBR Fabric 也有三种初始化模式:
- 静态 Fabric 初始化 (Static Fabric Initialization):
- 特点: 无需 FM。 所有配置,包括 PID 分配、路由表 (DRT/RGT)、端点绑定等,都在交换机启动时通过预定义的配置文件静态加载。
- 限制: 这种模式不支持 G-FAM 或 MLD,也不支持运行时的动态绑定变更。
- Fabric Manager (FM) 优先启动:
- 流程: FM 在所有主机启动前完成工作。 主机在此期间保持在复位状态。
- 步骤: FM 启动后,会发现 Fabric 拓扑,声明对所有组件的管理所有权,分配 PID,配置 GFD,并将端点绑定到 VCS。 当主机启动时,它看到的是一个已经完全配置好的系统。
- Fabric Manager (FM) 和主机同时启动:
- 流程: FM 和主机大致同时启动。
- 步骤: VCS 和 PID 等基本配置是静态的,但 vPPB 初始为未绑定状态。 主机启动后先枚举到一个“空的”虚拟层次结构。 与此同时,FM 开始发现设备并执行绑定操作,每次绑定都会以“热添加”事件的形式通知给主机。
7.7.12.2 PBR Fabric 发现
这是 FM 理解整个 Fabric 物理拓扑至关重要的一步,通常按以下流程进行:
声明所有权: FM 首先发现与自己直接相连的组件(通常是一个 PBR 交换机),并使用
Claim Ownership命令声明自己是其主 FM。 这是一个强制步骤,PBR 设备只接受其主 FM 发出的大部分管理命令。
探索交换机端口: FM 作为主 FM 后,可以查询该交换机的能力和端口状态。 它使用
Get Physical Port State和Get PBR Link Partner Info等命令来识别每个端口另一端连接的是什么类型的设备。
向外探索 (Fabric Crawl Out): 这是发现过程的核心。
- FM 使用
Fabric Crawl Out命令来管理连接在当前交换机端口远端的设备。
- 初次通信: 对于一个尚未分配 PID 的远端设备,FM 会以端口号作为目标,将命令隧道化发送过去。
- 分配 PID: FM 为这个远端设备分配一个唯一的 PID。
- 更新路由: FM 更新本地交换机的路由表 (DRT),建立从这个新 PID 到对应端口的路由规则。
- 后续通信: 完成路由更新后,FM 就可以直接以这个新分配的 PID 作为目标,继续使用
Fabric Crawl Out命令与该远端设备通信。
- FM 使用
重复: FM 重复步骤 1-3,直到整个 Fabric 中的所有 PBR 交换机和设备都被发现和分配了 PID。
7.7.12.3 分配和绑定 PID
- PID 分配: 在发现拓扑后,FM 使用
Configure PID Assignment命令为 Fabric 中的各个目标(如主机上行口、设备下行口、交换机间 Fabric 端口)分配 PID。
- 绑定操作:
Bind vPPB命令: 用于将一个直接连接的设备或 MLD 中的 LD 绑定到一个交换机的 VCS 中。
Configure PID Binding命令: 用于创建跨交换机的虚拟连接。 这是一个两步操作,分别在主机端边缘交换机 (Host ES) 和下游端边缘交换机 (Downstream ES) 上进行配置,从而将 Host ES 的 vDSP 与 Downstream ES 的 vUSP 绑定起来。
7.7.12.4 通过 CDAT 报告 Fabric 路由性能
- 主机需要通过 CDAT(能力数据表)获取内存的延迟和带宽信息。
- 对于 LD-FAM: 下游边缘交换机 (Downstream ES) 负责报告 CDAT 信息。这个信息会包含它自身的性能数据,并叠加上在进行 vDSP-vUSP 绑定时由 FM 提供的 Fabric 路由路径的性能数据。
- 对于 G-FAM: 主机通过 GAE 使用 CCI 命令来查询 CDAT。 GAE 负责为 FAST 表中的每个段生成 CDAT 信息。
7.7.12.5 在 PBR Fabric 中配置 CacheID
- 这个过程是自动化的。 主机像在 HBR 拓扑中一样配置下游交换机的 CacheID 路由表。
- 当主机完成配置并置位
Commit位时,下游边缘交换机会自动向主机边缘交换机发送一个名为RTUpdate的 VDM 消息,主机边缘交换机收到后会相应地配置其内部的 ID 到 PID 的转换逻辑。
7.7.12.6 动态 Fabric 变更
FM 和 PBR 交换机协同处理运行时的系统配置变更。
- 热添加/链路建立: 在一个未绑定的边缘端口上发生新的链路建立事件时,交换机会通知 FM,由 FM 接管后续的管理和绑定。
- 动态配置变更: FM 可以触发绑定/解绑(在主机看来是热添加/移除),或更新 G-FAM/GIM 的访问权限向量 (GMV/VTV),这些变更会触发对主机的通知。
- 热移除/链路中断:
- 当 Fabric 中发生链路中断事件时,交换机会通知 FM。
- FM 负责处理所有受影响的绑定关系(如解绑 vDSP/vUSP),并更新路由表或访问权限,以应对拓扑变化。